- Published on
CPU 성능 향상 기법과 메모리와 캐시메모리
- Authors
- Name
- 손예지(Liv)


본 시리즈는 혼자 공부하는 컴퓨터 구조 책을 스터디 하며 남기는 기록 중 세번째 시리즈 입니다. 이전 시리즈 보러가기
CPU 성능 향상 기법
05_1 빠른 CPU를 위한 설계 기법
- 클럭
- 단위 : 헤르츠(Hz)
- 코어 : 명령어를 실행하는 부품
- -> 명령어를 실행하는 부품을 여러개 포함하는 부품으로 의미 변화
- 8코어 : 명령어를 실행하는 부품의 모음이 8개
- -> 명령어를 실행하는 부품을 여러개 포함하는 부품으로 의미 변화
- 멀티코어 CPU/ 멀티코어 프로세서 : 코어를 여러개 포함하고 있는 CPU
- Q. 코어를 늘리는것과 연산 속도가 비례할까?
- 비례하지 않는다. 코어마다 처리 할 연산을 분배하는 것이 연산속도에 영향
- Q. 코어를 늘리는것과 연산 속도가 비례할까?
- 스레드와 멀티스레드
- 하드웨어적 스레드
- 2코어 4스레드 CPU
- 명령어 실행하는 부품 2개 포함, 한번에 네개의 명령어 처리할 수 있는 CPU --> 멀티스레드 프로세서
- 하이퍼스레딩(hyper-threading)
- 인텔의 멀티스레드 기술 의미
- 2코어 4스레드 CPU
- 소프트웨어적 스레드
- 하나의 프로그램에서 독립적으로 실행되는 단위
- 하드웨어적 스레드
- 멀티스레드 프로세서
- 레지스터를 여러개 가지고 있으면 여러개의 명령어를 동시에 처리할 수 있다
- 하나의 코어로 여러개의 명령어 처리할 수 있다
- 하드웨어 스레드 = 논리 프로세서
- 레지스터를 여러개 가지고 있으면 여러개의 명령어를 동시에 처리할 수 있다
05_2 명령어 병렬 처리 기법
- 명령어를 동시에 처리해 CPU를 쉬지않고 작동시키는 기법
- 명령어 파이프라인
- 명령어 처리 과정
- 명령어 인출 -> 명령어 해석 -> 명령어 실행 -> 결과 저장
- 같은 단계가 겹치지 않는다면 CPU는 동시 실행 가능
- 한 명령어를 해석하는 동안 다른 명령어를 인출 가능
- 명령어를 명령어 파이프라인에 넣고 처리하는거 -> 명령어 파이프라이닝(Instruction Pipelining)
- 명령어 파이프라인이 특정 상황에서 실패 -> 파이프라인 위험(Pipeline hazard)
- 데이터 위험
- 두 명령어가 데이터 의존성을 가지고 있는 경우 동시에 실행하려고 하면 처리 불가
- 제어 위험
- 프로그램 카운터의
- 분기 예측 : 프로그램의 분기를 예측해서 주소를 인출
- 프로그램 카운터의
- 구조적 위험
- 데이터 위험
- 명령어 처리 과정
- 슈퍼스칼라
- CPU 내부에 여러 개의 명령어 파이프라인 포함한 구조
- 이론적으로는 좀 더 빠르다
- 그치만 실제로는 파이프라인 개수에 비례해 빨라지지 않음
- CPU 내부에 여러 개의 명령어 파이프라인 포함한 구조
- 비순차적 명령어 처리(Out-of-order execution; OoOE)
- 명령어를 순차적으로 처리하지 않는 것
- 순서를 바꿔서 실행해도 되는 명령어를 먼저 수행
- 의존성
05_3 CISC와 RISC
- 명령어 집합, 명령어 집합 구조(Instruction Set Architecture) : CPU가 이해할 수 있는 명령어 모음
- 아이폰(ARM ISA)과 x86 ISA는 서로 이해할 수 있는 명령어가 달라 사용할 수 없음
- CISC(Complex Instruction Set Complex)
- 복잡한 명령어 집합을 활용하는 컴퓨터(CPU)
- 가변 길이 명령어
- 장점 : 적은 수의 명령어로도 프로그램 실행
- 단점 : 명령어의 크기, 실행되기까지 시간이 일정하지 않음 -> 명령어의 규격화 어려움
- 명령어 파이프라인의 명령어 처리 효율 떨어짐
- 자주 사용되는 명령어만 사용되고 복잡한 명령어는 사용 잘 안됨
- RISC(Reduced Instruction Set Complex)
- 고정 길이 명령어 -> 1클럭 내로 실행되는 명령어 지향
- 메모리에 직접 접근하는 명령어 load, store 두개로 제한
- 단순화 최소화 추구
메모리와 캐시 메모리
06_1 RAM의 특징과 종류
- 특징
- RAM : 휘발성 저장 장치
- 보조기억장치 : 비휘발성 저장 장치
- DRAM(Dynamic RAM)
- 일정 시간 이후 데이터 사라짐
- 일정 주기로 데이터 재활성화 필요
- 일반적으로 메모리로 사용하는 RAM
- SRAM(Static RAM)
- 시간이 지나도 데이터 유지
- 전원이 공급되지 않으면 저장된 내용 사라짐
- 시간이 지나도 데이터 유지
- SDRAM(Synchronous Dynamic RAM)
- 클럭신호와 동기화된 DRAM
- DDR SDRAM(Double Data Rate SDRAM)
- 대역폭(데이터를 주고받는 길의 너비)을 넓혀 속도를 빠르게 만든 SDRAM
- SDR SDRAM(Single Data Rate SDRAM) : 한 클럭당 하나씩 데이터 주고받을 수 있는 SDRAM
06_2 메모리의 주소 공간
- 논리주소
- CPU와 실행중인 프로그램이 사용하는 주소
- 물리주소
- 메모리 하드웨어가 사용하는 주소
- CPU가 메모리와 상호작용하려면 논리주소 - 물리주소 간 변환 필요
- 메모리 관리 장치(Memory Management Unit)
- CPU와 주소 버스 사이에 위치
- 논리 주소 + 베이스 레지스터 값을 더해 변환
- 메모리 관리 장치(Memory Management Unit)
- 논리 주소 범위 벗어나지 않도록 한계 레지스터(limit register)
06_3 캐시 메모리
- 저장 장치 계층 구조(memory hierarchy)
- 저장장치가 CPU에 가까울수록 빠르고, 용량이 작으면서 비싸다
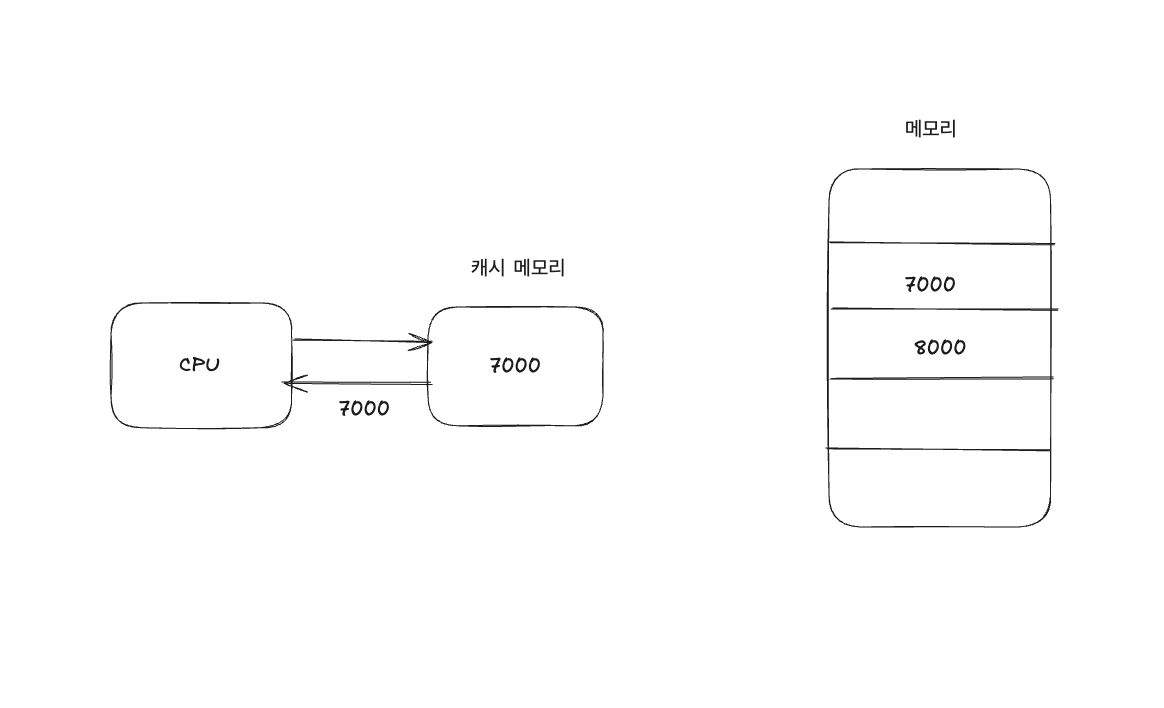
- 캐시 메모리
- 프로그램을 실행하는 동안 CPU가 메모리에 계속 접근해야 하기 때문에 캐시 메모리 필요성 대두
- 목적 :
CPU 연산 속도 <-> 메모리 접근 속도간 차이 줄이기 위해 - CPU - 메모리 사이에 위치
- 캐시 메모리 종류
- L1, L2는 코어 내부
- L3는 코어 외부
- 참조 지역성 원리(Locality of reference)
- 캐시 메모리는 CPU가 사용할 대상 예측해 저장
- 캐시 히트(cache hit) : 예측한 데이터가 일치할 경우
- 캐시 미스 (cache miss) : 예측이 틀려 메모리에서 데이터를 가져와야 하는 경우
- 캐시 적중률(cache hit radio) : 캐시가 히트되는 비율
캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수) - 캐시 적중률 높으면 캐시 메모리 성능 향상
- 참조 지역성의 원리
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다
- 시간 지역성(temporal locality)
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다
- 공간 지역성(spatial locality)
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다
알게된점
캐시 메모리와 참조 지역성에 대해서 공부하며 Redis 캐시를 활용하는 부분에 대해서 다시 한 번 알아보게 되었습니다. CPU에서 내부 캐시를 사용해 캐시 적중률을 높이는 것 처럼 Redis를 사용해 자주 조회되는 데이터를 Redis에 저장해 많은 요청을 Redis에서 처리해 DB조회 성능을 개선 하는 부분을 연결해 생각해 볼 수 있었습니다.